

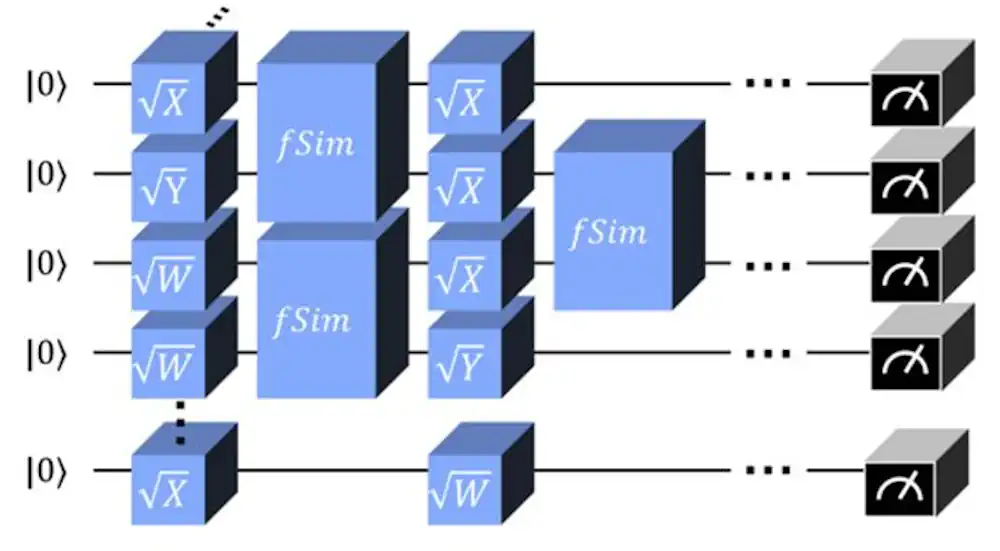
Des chercheurs ont récemment franchi une étape décisive dans l’informatique quantique en simulant avec succès le circuit quantique Sycamore de Google, composé de 53 qubits et de 20 couches. Cet exploit a été rendu possible grâce au déploiement d’algorithmes parallèles hautement optimisés sur 1 432 GPU NVIDIA A100, ouvrant la voie à de nouvelles possibilités dans les simulations classiques de systèmes quantiques.
Innovation dans les algorithmes efficaces
L’utilisation de techniques sophistiquées de contraction de réseaux tensoriels, qui permettent une approximation efficace des probabilités de sortie, est au cœur de cette avancée. L’équipe de recherche a utilisé des méthodes de découpage avancées pour diviser le réseau tensoriel en de nombreux sous-réseaux gérables, réduisant ainsi considérablement l’utilisation de la mémoire tout en maintenant l’efficacité des calculs. Cette approche permet de simuler des circuits quantiques complexes avec des ressources informatiques relativement modestes.
En outre, les chercheurs ont utilisé une méthode « top-k » pour sélectionner les k chaînes de bits les plus probables de l’échantillon prétraité. En se concentrant sur ces chaînes de bits à forte probabilité, ils ont obtenu une amélioration substantielle de la valeur de l’entropie croisée linéaire (XEB), une mesure clé de la fidélité de l’échantillonnage. Cette approche a permis non seulement de réduire les exigences de fidélité pour les simulations classiques, mais aussi de réduire la complexité des calculs et d’améliorer l’efficacité globale des simulations.
Expériences et validation
Pour valider leur algorithme, les chercheurs ont mené des expériences numériques avec des circuits aléatoires à plus petite échelle, notamment un circuit de 30 qubits à 14 couches. Les résultats ont montré une excellente concordance avec les valeurs XEB prédites par la théorie pour différentes tailles de sous-réseaux de contraction tensorielle. L’amélioration de la valeur XEB par la méthode top-k s’aligne étroitement sur les prédictions théoriques, ce qui confirme la précision et l’efficacité de l’algorithme.
Optimisation de la contraction du tenseur
L’étude a également mis en évidence des stratégies d’optimisation des besoins en ressources pour la contraction des tenseurs. En affinant l’ordre des indices des tenseurs et en minimisant la communication entre les GPU, l’équipe a obtenu des améliorations notables en termes d’efficacité de calcul. Cette stratégie démontre également, sur la base d’estimations de la complexité, que l’augmentation de la capacité de la mémoire (80 Go, 640 Go et 5120 Go) peut réduire de manière significative la complexité du temps de calcul. L’utilisation de configurations de mémoire de 8×80 Go par nœud de calcul a permis un calcul à haute performance.
Perspectives d’avenir
Cette percée établit non seulement une nouvelle référence pour les simulations classiques d’ordinateurs quantiques multiqubits, mais elle introduit également des outils et des méthodologies innovants pour les futures recherches sur l’informatique quantique. En continuant à affiner les algorithmes et à optimiser les ressources informatiques, les chercheurs prévoient de faire des progrès substantiels dans la simulation de circuits quantiques plus grands avec plus de qubits. Ces travaux représentent une avancée significative dans le domaine de l’informatique quantique et offrent des perspectives précieuses pour le développement continu des technologies quantiques.
Article : « Leapfrogging Sycamore: harnessing 1432 GPUs for 7× faster quantum random circuit sampling » – DOI : https://doi.org/10.1093/nsr/nwae317












